數(shù)據(jù)生產(chǎn)垂直大模型研發(fā)項目可行性研究報告
思瀚產(chǎn)業(yè)研究院 海天瑞聲 2023-06-25
1��、項目背景
(1)受大模型技術驅(qū)動�����,全球人工智能產(chǎn)業(yè)進入加速發(fā)展期,快速提升大模型相關技術能力成為國家新興科技發(fā)展戰(zhàn)略
人工智能大模型因其良好的泛化性和遷移性���,有助于推動人工智能進入大規(guī)模落地應用���,已成為人工智能發(fā)展新賽道。同時其強大的理解和生成能力���,將驅(qū)動人工智能技術加速與實體產(chǎn)業(yè)融合���,并深刻改變未來人類的生活和工作方式��,發(fā)展大模型技術成為全球各國比拼科技實力�����,提升經(jīng)濟效率����,拉升經(jīng)濟增長的重要動能之一����。
目前,國際巨頭紛紛布局以大模型為核心的通用人工智能產(chǎn)業(yè)���,產(chǎn)業(yè)進入加速發(fā)展期����。在這一信息技術重點領域�,我國與國際巨頭存在一定差距,正加速布局和應對�。國內(nèi)眾多研究機構、企業(yè)積極研究生成式AI大模型技術的最優(yōu)路徑����,并進行產(chǎn)品發(fā)布�。近期�,在國內(nèi)科技及投資各領域的高度關注下,百度��、商湯���、阿里巴巴�����、華為����、科大訊飛�、360�����、京東���、字節(jié)跳動等企業(yè)均有所行動��。
我國在“十四五”期間��,針對人工智能的未來發(fā)展陸續(xù)出臺了相關指導方案和激勵政策�����,對人工智能的整體發(fā)展方向和技術發(fā)展重點做出重要規(guī)劃���,同時提出加強算法創(chuàng)新與應用��、推動算力基礎設施建設�����、完善數(shù)據(jù)基礎支撐體系等關鍵建議��,倡導未來不斷夯實產(chǎn)業(yè)發(fā)展新基礎����。
全國各地亦陸續(xù)出臺多項數(shù)據(jù)政策����,其中,《北京市促進通用人工智能創(chuàng)新發(fā)展的若干措施》明確提出要“系統(tǒng)構建大模型等通用人工智能技術體系:開展大模型創(chuàng)新算法及關鍵技術研究����;加強大模型訓練數(shù)據(jù)采集及治理工具研發(fā)��;建設大模型評測開放服務平臺�;構建大模型基礎軟硬件體系�����。推動通用人工智能技術創(chuàng)新場景應用�。
《北京市加快建設具有全球影響力的人工智能創(chuàng)新策源地實施方案(2023-2025 年)》提出“到 2025 年,人工智能基礎理論研究取得突破�;關鍵核心技術基本實現(xiàn)自主可控,其中部分技術與應用研究達到世界先進水平�;人工智能高水平應用深度賦能實體經(jīng)濟,促進經(jīng)濟高質(zhì)量發(fā)展”的目標�����,并進一步提出了“自然語言����、通用視覺�����、多模態(tài)交互大模型等形成完整技術棧;生成式產(chǎn)品成為國內(nèi)市場主流應用和生態(tài)平臺”等具體目標���。
(2)人工智能大模型正處于產(chǎn)業(yè)發(fā)展轉(zhuǎn)型關鍵期��,垂直應用面臨爆發(fā)
在大模型通用性����、泛化性以及擴大人工智能應用范圍的優(yōu)勢推動下�,人工智能加快與各類產(chǎn)業(yè)的滲透和融合。人工智能大模型正處于打造商業(yè)模式����,形成基礎設施能力的關鍵時期,將從通用逐漸走向垂直領域�,在基礎模型之上的垂直行業(yè)應用也有望興起。大模型在搜索����、推薦、智能交互���、生產(chǎn)流程變革�、產(chǎn)業(yè)提效等場景已表現(xiàn)出了較大的潛力。例如�����,在金融領域���,陸續(xù)產(chǎn)生了通過構建大語言
模型等解讀征信報告���、實現(xiàn)交互式智能客服,為金融服務提質(zhì)增效賦能��。目前����,國內(nèi)相關機構及頭部企業(yè)在深耕通用基礎大模型研發(fā)之外,同時根據(jù)自身產(chǎn)業(yè)生態(tài)布局����,打造垂直領域大模型,觸達應用場景落地���;其他具備模型自研能力的肩部廠商��,亦基于開源模型或海量數(shù)據(jù)���,打造垂向大模型,建立垂直行業(yè)的平臺生態(tài)��。
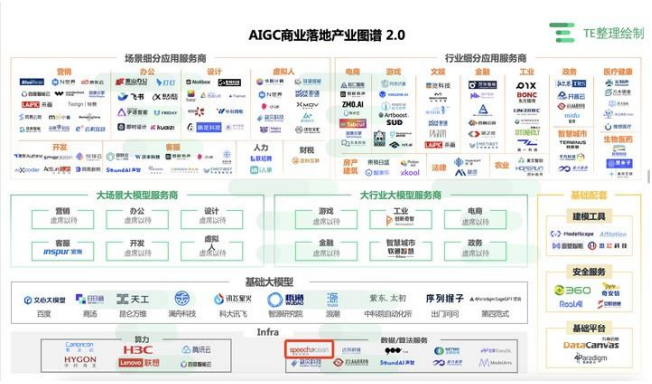
我國 AIGC 商業(yè)落地產(chǎn)業(yè)圖譜如下圖所示
來源:億歐·TE《中國AIGC商用場景趨勢捕捉指北》
由于大模型在垂直領域應用場景中����,需要依賴垂直領域數(shù)據(jù)和行業(yè)know-how、應用場景和用戶數(shù)據(jù)反哺以及一站式端到端工程化能力等�����。因此��,為實現(xiàn)通用大模型對行業(yè)應用的賦能��,需要相關領域機構或服務提供商基于通用大模型進行知識遷移���,建設行業(yè)垂向大模型����,實現(xiàn)其縱向業(yè)務價值���。
(3)大模型對人工智能數(shù)據(jù)處理技術提出了新要求��,該類技術的持續(xù)提升是支撐大模型長期發(fā)展���、持續(xù)服務垂直應用的必備能力
目前人工智能進入大模型時代���,大規(guī)模、高質(zhì)量數(shù)據(jù)的重要性愈加凸顯��,并成為模型訓練效果的核心支撐之一�,但在數(shù)據(jù)前沿性及工程化技術方面依然充滿挑戰(zhàn)。長期來看�,AI數(shù)據(jù)處理技術的持續(xù)拓新與發(fā)展是及時適應甚至超前引領大模型技術和應用發(fā)展的關鍵。
大模型研發(fā)的第一階段����,即預訓練階段,需要通過對海量未經(jīng)標注數(shù)據(jù)進行學習�,獲得"基本的語言能力和通用知識"。雖無需標注��,但這一階段需要對海量數(shù)據(jù)進行清洗����,清洗質(zhì)量的好壞,會顯著影響無監(jiān)督學習的效果及大模型的精準性���。在第二階段���,即強化學習階段,需要加入人類反饋�,人類以標注的方式對機器自學習后的判斷進行調(diào)整,使得大模型的認知和人類認知進行對齊����,亦構成大模型帶來優(yōu)質(zhì)體驗感的核心環(huán)節(jié)。
當前�����,業(yè)界已形成高度共識�����,即對于大模型訓練來說���,數(shù)據(jù)是模型訓練質(zhì)量的重要保障和核心要素�。若要訓練一個功能全面的高質(zhì)量大模型�,不僅需要持續(xù)獲取大規(guī)模、高質(zhì)量�、多模態(tài)��、多場景�����、多垂向的數(shù)據(jù)��,更需具備持續(xù)迭代的高質(zhì)量數(shù)據(jù)篩選����、清洗等技術和指令�、對齊、標注等策略�,以不斷提升包括預訓練階段、強化學習階段中所需數(shù)據(jù)的質(zhì)量�����,確保通用能力及各垂直應用能力的提升�����,為大模型精確性����、通用性及泛化能力的實現(xiàn)奠定堅實基礎����。
2����、項目基本情況
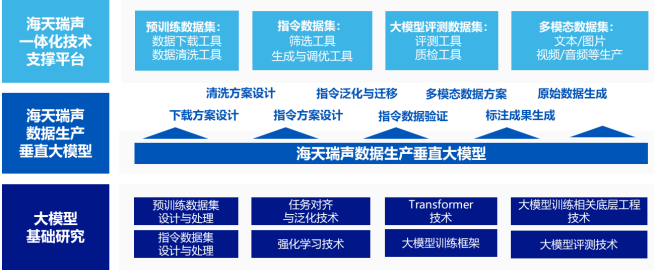
本項目建設目標為研發(fā)海天瑞聲數(shù)據(jù)生產(chǎn)垂直大模型,并以海天瑞聲數(shù)據(jù)生產(chǎn)垂直大模型為核心�,升級海天瑞聲一體化技術支撐平臺��。
大模型所需數(shù)據(jù)不同于傳統(tǒng)有監(jiān)督學習范式下的數(shù)據(jù)需求���,數(shù)據(jù)規(guī)模量級大���,且近年隨著數(shù)據(jù)安全環(huán)境快速驅(qū)嚴,數(shù)據(jù)使用權限和范圍受到更多的限定��,因此大模型時代下的數(shù)據(jù)處理規(guī)則將顯著區(qū)別于傳統(tǒng)方式����。此外,由于大模型訓練數(shù)據(jù)本身具有更高的復雜性和多樣性����,其數(shù)據(jù)服務規(guī)則的設計難度也將指數(shù)級提升�。
因此���,為更高效高質(zhì)完成數(shù)據(jù)規(guī)則的規(guī)?�;a(chǎn)���,公司將采用全棧自研的數(shù)據(jù)生產(chǎn)垂直大模型技術,輔助完成面向多個下游任務的數(shù)據(jù)設計與處理規(guī)則����,形成下載方案設計、清洗方案設計���、指令方案設計�����、指令泛化與遷移��、指令數(shù)據(jù)驗證���、多模態(tài)數(shù)據(jù)方案等多項生成能力,以及在上述方案下的原始數(shù)據(jù)及標注成果生成能力。
同時�����,為更好實現(xiàn)數(shù)據(jù)生產(chǎn)垂直大模型下的各類生成能力��,公司將研發(fā)并引入預訓練數(shù)據(jù)集設計與處理技術�、指令數(shù)據(jù)集設計與處理技術、任務對齊與泛化技術�����、強化學習技術���、Transformer技術、大模型訓練框架技術����、大模型訓練相關底層工程技術、大模型評測技術等�����,夯實數(shù)據(jù)生產(chǎn)垂直大模型構建的基礎���。
此外��,基于數(shù)據(jù)生產(chǎn)垂直大模型的核心能力����,項目還將升級海天瑞聲一體化技術支撐平臺,使其能夠全面擁有大模型范式下的數(shù)據(jù)服務能力��。通過嵌入預訓練數(shù)據(jù)下載工具�、預訓練數(shù)據(jù)清洗工具、指令數(shù)據(jù)集篩選工具�、指令數(shù)據(jù)集生成與調(diào)優(yōu)工具、大模型評測數(shù)據(jù)集評測工具�、大模型評測數(shù)據(jù)集質(zhì)檢工具、多模態(tài)數(shù)據(jù)集生產(chǎn)工具等模塊�����,完成大模型的數(shù)據(jù)獲取與處理工作��,打造模型訓練��、模型評測的能力�。
海天瑞聲新一代基于數(shù)據(jù)生產(chǎn)垂直大模型的數(shù)據(jù)服務技術架構圖
3、項目建設必要性
(1)本項目建設是公司落實國家科技創(chuàng)新發(fā)展戰(zhàn)略的重要舉措
人工智能是戰(zhàn)略性新興產(chǎn)業(yè)的重要組成部分�����,對我國經(jīng)濟發(fā)展和提升國家戰(zhàn)略安全具有重要意義。在世界政治經(jīng)濟格局加速重構的影響下���,未來逆全球化趨勢仍將延續(xù)�。全球產(chǎn)業(yè)合作格局重構����、國際分工體系全面調(diào)整,關鍵環(huán)節(jié)的國際競爭將加劇��,我國在關鍵核心技術上的問題愈發(fā)突出����,戰(zhàn)略性新興產(chǎn)業(yè)的產(chǎn)業(yè)鏈安全穩(wěn)定存在潛在隱患。
因此��,我國需要進一步集中優(yōu)勢資源�����,在重點領域加快突破一批關鍵核心技術���,助力提升我國新興產(chǎn)業(yè)的產(chǎn)業(yè)鏈關鍵環(huán)節(jié)、關鍵領域、關鍵產(chǎn)品的安全保障能力���,保障國家戰(zhàn)略安全��。
公司是我國人工智能數(shù)據(jù)服務領域的龍頭提供商���,本項目以研發(fā)數(shù)據(jù)生產(chǎn)垂直大模型為核心,并基于該生產(chǎn)大模型對數(shù)據(jù)集生產(chǎn)的強大支撐能力�,升級海天瑞聲一體化技術支撐平臺,持續(xù)以自主可控的技術與平臺為我國人工智能技術與產(chǎn)業(yè)發(fā)展提供支撐�。本項目的建設是公司落實國家科技創(chuàng)新發(fā)展戰(zhàn)略的重要舉措。
(2)本項目建設是鞏固公司的核心技術壁壘��,構建長期技術實力的必然手段
隨著人工智能從深度學習階段走向大模型階段��,對訓練數(shù)據(jù)服務產(chǎn)生了新的需求���,具體可分為預訓練階段和強化學習階段:在預訓練階段�,模型所需的數(shù)據(jù)量巨大��;在強化學習階段����,模型所需的數(shù)據(jù)質(zhì)量較高�,并需要以相關領域 know-how 作為模型輸入����。此外,隨著多模態(tài)大模型的不斷發(fā)展��,跨語音���、文本和視頻圖像數(shù)據(jù)等多種類別的數(shù)據(jù)集需求將快速增加�。
數(shù)據(jù)集生產(chǎn)能力和一體化技術支撐平臺是公司核心技術的重要體現(xiàn)�����。目前ChatGPT 等模型執(zhí)行通用生成任務的效果證明了大模型可具備數(shù)據(jù)生成能力����。本項目的建設將基于公司在深度學習階段數(shù)據(jù)集生產(chǎn)所積累的 know-how,自主研發(fā)數(shù)據(jù)生產(chǎn)垂直大模型����,構建大模型數(shù)據(jù)處理技術通用化解決方案能力,實現(xiàn)完整�����、可持續(xù)迭代的大模型數(shù)據(jù)技術框架和數(shù)據(jù)策略�����,進一步提高公司在人工智能基礎數(shù)據(jù)服務領域的智能化水平��,鞏固公司的核心技術壁壘��,形成長期技術實力支撐�。
(3)本項目建設是提升公司數(shù)據(jù)服務綜合競爭力的有效途徑
大模型訓練數(shù)據(jù)集的生產(chǎn)流程包括設計、獲?���。P蜕桑⑶逑?����、標注�、安全管理、質(zhì)控評測等不同的環(huán)節(jié)���。系統(tǒng)化的開發(fā)平臺和專業(yè)化的軟件處理工具對應對大模型時代的數(shù)據(jù)處理需求和全流程支撐至關重要�����。本項目有助于進一步優(yōu)化公司的數(shù)據(jù)處理技術����,促進數(shù)據(jù)資源處理經(jīng)驗的進一步沉淀,長期來看��,可以大幅提高公司的數(shù)據(jù)處理能力�����、效率�����,提升服務范圍和水平��,適應人工智能發(fā)展的新階段��,獲得有效長期的發(fā)展動力�����,進一步鞏固和提升公司在數(shù)據(jù)服務領域的競爭力�。
4、項目建設可行性
(1)本項目建設符合政策要求和行業(yè)發(fā)展趨勢
2023 年 4 月 11 日����,國家互聯(lián)網(wǎng)信息辦公室公布《生成式人工智能服務管理辦法(征求意見稿)》,文件明確指出���,“國家支持人工智能算法��、框架等基礎技術的自主創(chuàng)新����、推廣應用�����、國際合作��,鼓勵優(yōu)先采用安全可信的軟件����、工具、計算和數(shù)據(jù)資源”�,“用于生成式人工智能產(chǎn)品的預訓練、優(yōu)化訓練數(shù)據(jù)���,應滿足法律法規(guī)要求��、不侵權���、同時保證數(shù)據(jù)真實性�����、準確性�����、客觀性�����、多樣性等若干要求�����?�!痹撧k法從政策層面對生成式人工智能的數(shù)據(jù)集提出了明確的合法�、合規(guī)����、合理���、準確以及知識產(chǎn)權清晰的高要求。
但目前國內(nèi)大模型的發(fā)展普遍存在數(shù)據(jù)來源不均衡��、數(shù)據(jù)更新實時性弱�、垂直類型數(shù)據(jù)不足��、指令集質(zhì)量欠佳且存在偏見等問題����,由此導致大模型的效果、效率����、合規(guī)性、合理性等方面亟待完善與提升��,且在大模型持續(xù)發(fā)展過程中���,部分問題的影響可能持續(xù)擴大��。因此���,建立一套完整�、完善��、可持續(xù)迭代的大模型訓練數(shù)據(jù)技術框架和數(shù)據(jù)策略�,符合生成式人工智能技術與應用合規(guī)、高效發(fā)展的趨勢����。
(2)公司與現(xiàn)有客戶、科研院所聯(lián)系緊密�����,可確保項目技術框架明確��、技術路線可行有效
公司自 2005 年成立以來�����,始終致力于挖掘行業(yè)客戶需求����,解決客戶痛點,通過在智能語音���、計算機視覺����、自然語言等領域的技術積累,獲得全球眾多客戶認可�,截至 2022 年底,公司累計客戶數(shù)量已達到 810 家��。公司現(xiàn)有客戶包括阿里巴巴��、騰訊�、百度�、科大訊飛、?���?低暋⒆止?jié)跳動�����、微軟��、亞馬遜����、三星��、中國科學院���、清華大學等全球主流企業(yè)、教育科研機構以及政企機構����。
公司部分現(xiàn)有客戶是當前大模型領域的積極實踐者,通過與客戶的長期合作�,深度交流,能夠第一時間獲取大模型研發(fā)中數(shù)據(jù)痛點與需求��,并可在持續(xù)交流反饋中不斷修正本項目的建設方案�。此外,公司也與科研院所和高校等開展深入合作�,可引入外部專家資源,以保證技術路線的可行性���。
(3)公司擁有深厚的技術沉淀和人才儲備����,具有完成本項目的技術基礎
公司深耕行業(yè)近 20 年��,擁有一支高素質(zhì)的研發(fā)團隊,公司高管及核心研發(fā)人員大多畢業(yè)于清華�、北大、復旦等一流院校���,大部分曾在微軟�、阿里巴巴���、英特爾����、IBM��、中科院等業(yè)內(nèi)領先的成熟企業(yè)與研究機構擔任人工智能領域技術研發(fā)與管理的領導職務�。截至 2022 年 12 月 31 日��,公司研發(fā)人員達到 82 人��,經(jīng)驗豐富的技術團隊為本項目的執(zhí)行提供了人才保證�����。
截至 2022 年底�,公司擁有算法模型框架 16 個����、算法模型數(shù)量超過 200 個�����,公司自然語言理解算法支持包括語義理解�����、情感分析和意圖識別等能力����,語音識別算法支持語種 58 個,計算機視覺算法支持幾十大類���、上百小類的物體識別��。公司在智能語音�����、自然語言�、計算機視覺領域均有多年算法積累���,該等算法模型能夠全面支撐公司多個領域數(shù)據(jù)生產(chǎn)活動的開展����。
5、項目投資概算
本項目投資金額總量為 40,651.64 萬元��,投資明細主要包括場地購置及裝修費用��、設備購置費用��、軟件購置費用�、研發(fā)人員費用和設備托管費用。
6���、項目實施主體及實施計劃
(1)項目實施主體
本項目的實施主體為北京海天瑞聲科技股份有限公司及/或下屬子公司���。
(2)項目實施計劃
本項目建設期3年。
7�����、項目經(jīng)濟效益評價
本項目是公司落實發(fā)展戰(zhàn)略���,順應行業(yè)發(fā)展趨勢���,支撐公司加速數(shù)據(jù)服務領域算法能力建設、持續(xù)構建 AI 產(chǎn)業(yè)核心競爭力的必要手段����。本項目不直接產(chǎn)生效益,項目建成后將成為公司主營業(yè)務長期發(fā)展的技術底座���。
8�����、項目批準情況
目前���,本公司正在辦理本項目立項備案。
本項目不同于常規(guī)生產(chǎn)性項目�����,不存在廢氣���、廢水�����、廢渣等工業(yè)污染物����,不屬于根據(jù)《中華人民共和國環(huán)境影響評價法》和《建設項目環(huán)境影響評價分類管理名錄》等相關法律法規(guī)需要進行環(huán)境影響評價的建設項目。因此�����,本項目無需進行項目環(huán)境影響評價��,亦不需要取得環(huán)保主管部門對項目的審批文件��。
免責聲明:
1.本站部分文章為轉(zhuǎn)載�,其目的在于傳播更多信息,我們不對其準確性���、完整性�、及時性����、有效性和適用性等任何的陳述和保證。本文僅代表作者本人觀點����,并不代表本網(wǎng)贊同其觀點和對其真實性負責。
2.思瀚研究院一貫高度重視知識產(chǎn)權保護并遵守中國各項知識產(chǎn)權法律���。如涉及文章內(nèi)容��、版權等問題���,我們將及時溝通與處理。


業(yè)規(guī)劃")
計劃書")

規(guī)劃")


 美國亞利桑那州-記憶綿床墊生產(chǎn)基地擴建項目可行性研究報告
美國亞利桑那州-記憶綿床墊生產(chǎn)基地擴建項目可行性研究報告 江西宜春-高能量密度動力儲能(方形)鋰電池研發(fā)產(chǎn)業(yè)化項目可行性研究報告
江西宜春-高能量密度動力儲能(方形)鋰電池研發(fā)產(chǎn)業(yè)化項目可行性研究報告 水晶光電-臺州智能終端用光學組件技改項目可行性研究報告
水晶光電-臺州智能終端用光學組件技改項目可行性研究報告 廣西欽州-中偉股份北部灣產(chǎn)業(yè)基地三元項目一期可行性研究報告
廣西欽州-中偉股份北部灣產(chǎn)業(yè)基地三元項目一期可行性研究報告 中國天津-毫米波雷達研發(fā)中心建設項目可行性研究報告
中國天津-毫米波雷達研發(fā)中心建設項目可行性研究報告 中國重慶-國儲珞璜智慧物流園項目可行性研究報告
中國重慶-國儲珞璜智慧物流園項目可行性研究報告 安徽合肥-高性能微電子級聚酰亞胺膜材料項目可行性研究報告
安徽合肥-高性能微電子級聚酰亞胺膜材料項目可行性研究報告 廣東汕頭-生殖健康藥品整體升級項目可行性研究報告
廣東汕頭-生殖健康藥品整體升級項目可行性研究報告